本文共 5876 字,大约阅读时间需要 19 分钟。
日前,网约车服务商 Uber 开源并发布了它们开发的 Ludwig,这是一款基于 Google TensorFlow 框架上的开源工具箱。藉由 Ludwig,用户无需再编写任何代码即可进行深度学习的开发,AI 前线为读者们翻译了由 Uber AI 工程师们撰写的这篇文章,希望有所启示。
在过去的十年中,人们证明了深度学习在视觉、语音和语言方面执行各种各样的机器学习任务非常有效。Uber 将这些深度学习模型用于各种任务,包括客户支持、对象检测、改进地图、简化聊天沟通、预测和防止欺诈。
现在有很多开源库,包括 TensorFlow、PyTorch、CNTK 和 Chainer 等,已经实现了构建此类模型所需的构件,从而可以进行更快、更不易出错的开发。而这些反过来又推动了机器学习研究界和行业从业者采用这种模型,从而在架构设计和行业解决方案方面取得了快速的进展。
Uber AI 决定避免重新发明轮子,在开源库所提供的强大基础之上开发软件包。为此,Uber AI 于 2017 年发布了 Pyro,这是一种基于 PyTorch 的深度概率编程语言,并借助开源社区的力量继续改进。Uber 开发的另一个主要开源人工智能工具是 Horovod,这是由 LF 深度学习基金会(LF Deep Learning Foundation)托管的一个框架,允许在多个 GPU 和多台机器上对深度学习模型进行分布式训练。
Uber 在 TensorFlow 的基础上开发了一款开源深度学习工具箱,命名为 Ludwig,允许用户在无需编写代码的情况下即可训练并测试深度学习模型。
Ludwig 的独特之处在于它能够帮助非专家更容易地理解深度学习,并为经验丰富的机器学习开发者和研究人员提供更快的模型改进迭代周期。通过使用 Ludwig,专家和研究人员可以简化原型设计过程及数据处理,这样他们就可以专注于开发深度学习体系架构,而不是深陷数据整理。
Ludwig
在过去两年里,为了简化应用项目中深度学习模型的使用,因为它们通常需要在不同架构和快速迭代之间进行比较,Uber 内部一直在开发 Ludwig。Uber 已经见证了 Ludwig 对 Uber 自有的几个项目带来的价值,包括人工智能客服助理平台(Customer Obsession Ticket Assistant ,COTA)、驾照的信息提取、司乘之间对话兴趣点的识别、送餐速度预测等等。出于这些原因,Uber 决定开源并发布 Ludwig,因为他们认为目前还没有任何其他解决方案具有相同的易用性和灵活性。
Uber 最初将 Ludwig 设计为通用工具,用于在处理新的应用机器学习问题时简化模型开发和比较过程。为实现这一目标,Uber 从其他机器学习软件汲取了灵感:Weka 和 MLlib,它们直接处理原始数据并提供一定数量的预构建模型的想法;Caffe 定义文件的声明性;scikit-learn,一套简单的编程 API。这些灵感混合在一起,使得 Ludwig 迥异于常见的深度学习库,后者提供张量代数(tensor algebra)原语和很少的其他工具来编码模型,同时使 Ludwig 比 PyText、StanfordNLP、AllenNLP 和 OpenCV等其他专业库更加通用。
Ludwig 提供了一组模型架构,这些架构可以组合在一起,为给定的用例创建端到端模型。打个比方,如果说深度学习库为你的建筑提供了构建块,那么 Ludwig 就相当于构建城市的构建块,你可以选择可用的建筑物或你自己的建筑物添加到可用的建筑中。
Uber 在 Ludwig 工具箱中提出的核心设计原则是:
- 无需编码:该工具无需编码技能即可训练模型并将其用于获取预测。
- 通用性:一种新的基于数据类型的深度学习模型设计方法,使该工具可用于许多不同的用例。
- 灵活性:经验丰富的用户可以对模型构建和训练进行广泛的控制,而对新手而言,该工具易于使用。
- 可扩展性:该工具易于添加新的模型架构和新的特征数据类型。
- 可理解性:深度学习模型内部通常被认为是 “黑盒”,但 Uber 提供了标准的可视化来理解它们的性能并比较它们的预测。
Ludwig 允许用户通过仅提供包含数据的表格文件(如 CSV)和 YAML 配置文件来训练深度学习模型,YAML 配置文件指定表格文件的哪些列是输入特征,哪些列是输出目标变量。配置文件的简单性可以加快原型设计速度,从而有望将编码时间减少到几分钟。如果指定了多个输出目标变量,Ludwig 将执行多任务学习,学习同时预测所有的输出,而这通常需要定制代码。
模型定义可以包含附加信息,尤其是数据集中每个特征的预处理信息,用于每个特征的编码器或解码器,每个编码器和解码器的架构参数以及训练参数。预处理、训练和各种模型架构参数的默认值是依据 Uber 的经验选择的,或者是根据学术文献改变的,这样新手就可以轻松训练复杂的模型。同时,在模型配置文件中分别设置每一项的能力,为专家提供了充分的灵活性。使用 Ludwig 训练的每个模型都将会被保存,并且可以在以后加载来获得对新数据的预测。比如,模型可以被加载到服务环境中,这样就可以在软件应用中提供预测。
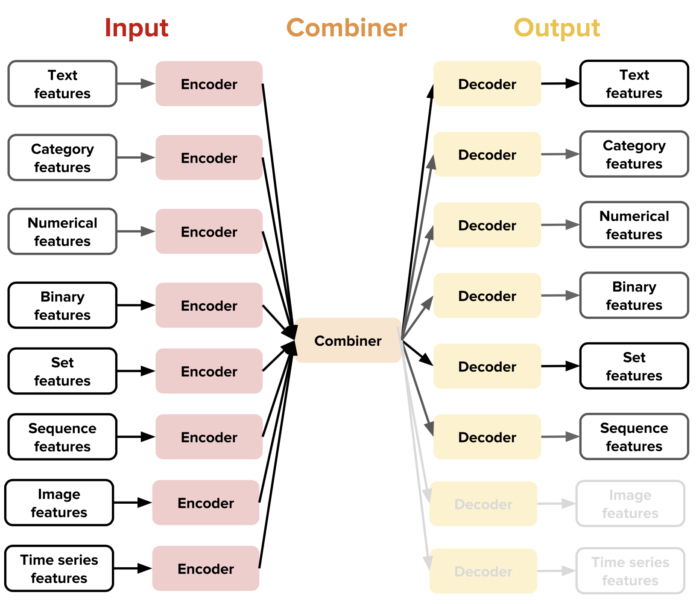
通过这种设计,用户可以访问组合器(架构的胶合组件),他们组合了来自所有输入编码器的张量,并进行处理,然后返回用于输出解码器的张量。例如,Ludwig 的默认合并多个数据组合器连接不同编码器的输出,将它们传递到完全连接的层,并提供最终激活作为输出解码器的输入。其他组合器可用于其他用例,通过实现简单的函数接口即可轻松添加更多的组合器。
通过组合这些特定于数据类型的组件,用户可以在各种任务上构建 Ludwig 训练模型。例如,通过组合文本编码器和类别编码器,用户可以获得文本分类器;而组合图像编码器和文本解码器则可获得图像字幕模型。
每种数据类型可以有多个编码器和解码器。例如,文本可以使用卷积神经网络(CNN)、递归神经网络(RNN)或其他编码器进行编码。然后,用户可以直接在模型定义文件中指定要使用的参数及超参数,而无需编写任何代码。
这种灵活多样的编码器 - 解码器架构使经验不足的深度学习从业者能够轻松地训练各种机器学习任务的模型,例如文本分类、对象分类、图像字幕、序列标记、回归、语言建模、机器翻译、时间序列预测和问答系统等。这就开启了各种用例,而这些用例对毫无经验的从业者而言通常是遥不可及的,并且还允许在一个领域中有经验的用户去接触新的领域。
目前,Ludwig 包含了二进制值、浮点数、类别、离散序列、集合、包、图像、文本和时间序列的编码器和解码器,以及加载一些预训练的模型(例如词嵌入)的功能。Uber 还计划在未来版本中继续扩展支持的数据类型。
除了可用性和灵活的架构外,Ludwig 还为非程序员提供了额外的好处。Ludwig 集成了一组用于训练、测试模型和获取预测的命令行实用程序。为了进一步提高可用性,工具箱还提供了一套编程 API,用户可以只需几行代码即可训练和使用模型。
此外,它还包括一套其他工具,用户评估模型,通过可视化来比较它们的性能和预测,并从中提取出模型权重和激活。
最后,通过使用开源分布式训练框架 Horovod,在多个 GPU 上以本地和分布式的方式训练模型,这一做法使得在模型上迭代和快速获得结果成为可能。
使用 Ludwig
为了更好地理解如何将 Ludwig 用于现实世界的应用程序,让我们用工具箱来构建一个简单的模型。在这个例子中,我们创建了一个模型,根据书名、作者、描述和封面来预测某本图书的类型和价格。
训练模型
我们的图书数据集如下表所示:
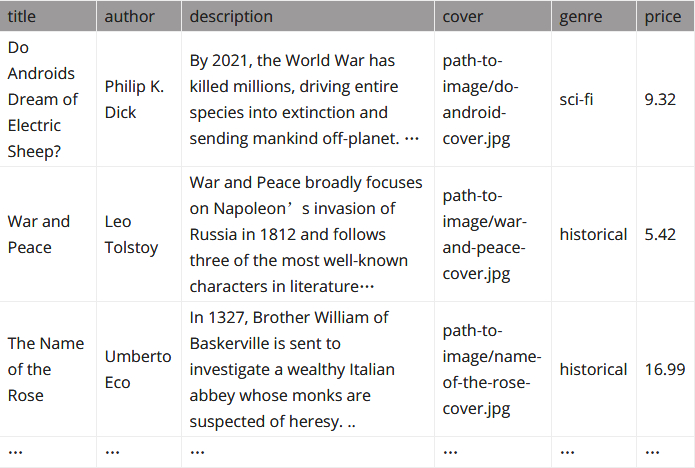
为了学习一种模型,这个模型使用标题、作者、描述和封面栏的内容作为输入来预测图书的类型和价格栏中的值,那么模型定义 YAML 应该如下所示:
input_features: – name: title type: text – name: author type: category – name: description type: text – name: cover type: imageoutput_features: – name: genre type: category – name: price type: numericaltraining: epochs: 10
我们在控制台输入以下命令开始训练:
ludwig train –data_csv path/to/file.csv –model_definition_file model_definition.yaml
通过上面这条命令,Ludwig 在训练、验证和测试集中的数据进行随机分割,对其进行预处理,并为四个输入构建四个不同的编码器,为两个输出目标构建一个组合器和两个解码器。然后,在训练集上对模型进行训练,直到验证集的正确度不再提高或者达到最大的十个轮数。
训练进度将会在控制台中显示,但也可以使用 TensorBoard 来显示训练进度。
默认情况下,文本特征由 CNN 编码器进行编码,但我们可以使用 RNN 编码器,使用状态大小为 200 的双向 LSTM 来编码标题。我们只需将标题编码器定义更改为如下所示:
name: titletype: textencoder: rnncell_type: lstmbidirectional: true
如果我们想要更改训练参数,如轮数、学习率和批大小,我们会像这样更改模型的定义,如下所示:
input_features: – …output_features: – …training: epochs: 100 learning_rate: 0.001 batch_size: 64
有关如何执行分割和数据预处理的所有参数,每个编码器组合器和解码器的参数都具有默认值,但它们是可配置的。用户可以参阅这本指南:,了解模型定义和训练参数,并查看 Uber 的示例,以了解 Ludwig 如何应用于几个不同的任务的。())
可视化训练结果
训练结束后,Ludwig 创建一个结果目录,其中包含了训练模型机器超参数和训练过程的汇总统计信息。我们可以使用可视化工具提供的几种可视化选项之一对它们进行可视化,例如:
ludwig visualize –visualization learning_curves –training_stats results/training_stats.json
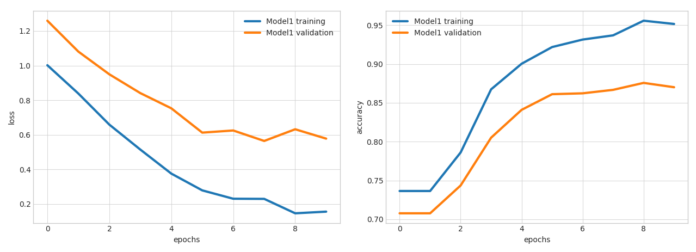
这样将显示如下图所示的图形,显示了作为训练轮数函数的损失和正确率:
还有几种可视化的方法可以用。用户指南中的可视化章节提供了更多的细节:
用已训练的模型预测结果
如果用户拥有新的数据,想用以前训练过的模型来预测目标输出值,可以键入如下命令:
ludwig predict –data_csv path/to/data.csv –model_path /path/to/model
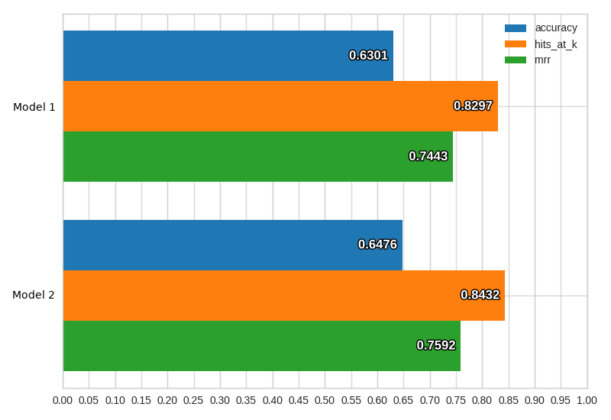
如果数据集包含与预测进行比较的真相信息,运行这条命令将会返回模型预测以及一些测试性能的统计信息。这些可以通过可视化命令(如上所示)进行可视化,也可用于比较不同模型的性能和结果预测,例如:
ludwig visualize –visualization compare_performance –test_stats path/to/test_stats_model_1.json path/to/test_stats_model_2.json
将返回一个柱状图,比较不同指标下的模型:
还有一条实验命令,无需使用两条单独的命令就可以先进行训练然后进行预测。
使用 Ludwig 的编程 API
Ludwig 还提供了一个简单的 Python 编程 API,可以让用户训练或加载模型并使用它来获取对新数据的预测:
# train a modelmodel_definition = {…}model = LudwigModel(model_definition)train_stats = model.train(training_dataframe)# or load a modelmodel = LudwigModel.load(model_path)# obtain predictionspredictions = model.predict(test_dataframe)model.close() 该 API 支持使用在现有代码中使用 Ludwig 培训的模型在其上构建应用程序。在用户指南()和 API 文档()中提供了使用 Ludwig 编程 API 的更多细节。
结论
Uber 决定将 Ludwig 开源发布,因为 Uber 相信,Ludwig 对非专业的机器学习从业者和经验丰富的深度学习开发人员及研究人员来说,都是一款有用的工具。藉由 Ludwig,非专家可以快速训练和测试深度学习模型,而无需编写一行代码。通过执行标准的数据预处理和可视化,专家可以获得强大的基线来比较他们的模型,并具有实验设置,可以轻松测试新想法和分析模型。
在未来的版本中,Uber 希望为每种数据类型添加几个新的编码器,例如用于文本的 Transformer、ELMo 和 BERT、用于图像的 DenseNet 和 FractaNet。Uber 还希望添加其他数据类型,如音频、点云和图形,同时集成更多可扩展的解决方案来管理大数据,如 Petastorm。
Uber 在开发 Ludwig 时考虑了可扩展性原则,为促进社区的贡献,Uber 还提供了开发人员指南:,这份指南表明了为现有数据类型添加额外的数据类型以及其他编码器、解码器都是一件简单的事。
原文链接:
转载地址:http://cqjbx.baihongyu.com/